
Apache Pig: Una introducción completa
¿Qué es Apache Pig?
Apache Pig es una capa de abstracción sobre MapReduce. Es una herramienta/plataforma utilizada para analizar grandes conjuntos de datos representándolos como flujos de datos. Pig se usa generalmente con Hadoop; podemos realizar todas las operaciones de manipulación de datos en Hadoop usando Apache Pig.
Para escribir programas de análisis de datos, Pig proporciona un lenguaje de alto nivel llamado Pig Latin. Este lenguaje proporciona varios operadores que permiten a los programadores desarrollar sus propias funciones para leer, escribir y procesar datos.
Para analizar datos usando Apache Pig, los programadores deben escribir scripts usando Pig Latin. Todos estos scripts se convierten internamente en tareas de mapa y reducción. Apache Pig tiene un componente llamado Pig Engine que acepta los scripts de Pig Latin como entrada y los convierte en trabajos de MapReduce.
¿Por qué necesitamos Apache Pig?
Los programadores que no son expertos en Java solían tener dificultades para trabajar con Hadoop, especialmente al realizar tareas de MapReduce. Apache Pig es una gran ayuda para estos programadores.
Usando Pig Latin, los programadores pueden realizar tareas de MapReduce fácilmente sin escribir código Java complejo.
Apache Pig utiliza un enfoque de consultas múltiples, lo que reduce la longitud del código. Por ejemplo, una operación que requeriría 200 líneas de código (LOC) en Java se puede realizar fácilmente escribiendo solo 10 LOC en Apache Pig. En última instancia, Apache Pig reduce el tiempo de desarrollo hasta 16 veces.
Pig Latin es un lenguaje similar a SQL, por lo que es fácil aprender Apache Pig si se está familiarizado con SQL.
Apache Pig proporciona muchos operadores integrados para admitir operaciones de datos como uniones, filtros, ordenamientos, etc. Además, proporciona tipos de datos anidados como tuplas, bolsas y mapas que no están presentes en MapReduce.
Características de Pig
Apache Pig viene con las siguientes características:
Rico conjunto de operadores: proporciona muchos operadores para realizar operaciones como join, sort, filter, etc.
Facilidad de programación: Pig Latin es similar a SQL y es fácil escribir un script de Pig si se domina SQL.
Oportunidades de optimización: las tareas en Apache Pig optimizan su ejecución automáticamente, por lo que los programadores solo deben centrarse en la semántica del lenguaje.
Extensibilidad: utilizando los operadores existentes, los usuarios pueden desarrollar sus propias funciones para leer, procesar y escribir datos.
UDF’s: Pig ofrece la posibilidad de crear funciones definidas por el usuario en otros lenguajes de programación como Java e invocarlas o incrustarlas en scripts de Pig.
Maneja todo tipo de datos: Apache Pig analiza todo tipo de datos, tanto estructurados como no estructurados. Almacena los resultados en HDFS.
Apache Pig vs. MapReduce
A continuación, se enumeran las principales diferencias entre Apache Pig y MapReduce.
| Apache Pig | MapReduce |
|---|---|
| Apache Pig es un lenguaje de flujo de datos. | MapReduce es un paradigma de procesamiento de datos. |
| Es un lenguaje de alto nivel. | MapReduce es de bajo nivel y rígido. |
| Realizar una operación de unión en Apache Pig es bastante simple. | En MapReduce es bastante difícil realizar una operación de unión entre conjuntos de datos. |
| Cualquier programador novato con conocimientos básicos de SQL puede trabajar cómodamente con Apache Pig. | La experiencia en Java es imprescindible para trabajar con MapReduce. |
| Apache Pig utiliza un enfoque de consulta múltiple, lo que reduce la longitud de los códigos en gran medida. | MapReduce requeriría casi 20 veces más líneas de código para realizar la misma tarea. |
| No hay necesidad de compilación. En la ejecución, cada operador de Apache Pig se convierte internamente en un trabajo de MapReduce. | Los trabajos de MapReduce tienen un largo proceso de compilación. |
Apache Pig vs. SQL
A continuación, se enumeran las principales diferencias entre Apache Pig y SQL.
| Pig | SQL |
|---|---|
| Pig Latin es un lenguaje de procedimiento. | SQL es un lenguaje declarativo. |
| En Apache Pig, el esquema es opcional. Podemos almacenar datos sin diseñar un esquema (los valores se almacenan como $01, $02, etc.) | El esquema es obligatorio en SQL. |
| El modelo de datos en Apache Pig es relacional anidado. | El modelo de datos utilizado en SQL es relacional plano. |
| Apache Pig ofrece una oportunidad limitada para la optimización de consultas. | Hay más oportunidades para la optimización de consultas en SQL. |
Además de las diferencias anteriores, Apache Pig Latin:
- Permite divisiones en la tubería.
- Permite a los desarrolladores almacenar datos en cualquier parte de la tubería.
- Declara planes de ejecución.
- Proporciona operadores para realizar funciones ETL (Extraer, Transformar y Cargar).
Apache Pig vs. Hive
Tanto Apache Pig como Hive se utilizan para crear trabajos de MapReduce. Y en algunos casos, Hive opera en HDFS de manera similar a Apache Pig. En la siguiente tabla, hemos enumerado algunos puntos importantes que distinguen a Apache Pig de Hive.
| Apache Pig | Hive |
|---|---|
| Apache Pig usa un lenguaje llamado Pig Latin. Originalmente fue creado en Yahoo. | Hive usa un lenguaje llamado HiveQL. Originalmente fue creado en Facebook. |
| Pig Latin es un lenguaje de flujo de datos. | HiveQL es un lenguaje de procesamiento de consultas. |
| Pig Latin es un lenguaje de procedimiento que encaja en el paradigma de pipeline. | HiveQL es un lenguaje declarativo. |
| Apache Pig puede manejar datos estructurados, no estructurados y semiestructurados. | Hive es principalmente para datos estructurados. |
Aplicaciones de Apache Pig
Apache Pig es generalmente utilizado por científicos de datos para realizar tareas que implican procesamiento ad-hoc y prototipado rápido. Apache Pig se usa:
- Para procesar grandes fuentes de datos, como registros web.
- Para realizar el procesamiento de datos para plataformas de búsqueda.
- Para procesar cargas de datos sensibles al tiempo.
Historia de Apache Pig
En 2006, Apache Pig se desarrolló como un proyecto de investigación en Yahoo, especialmente para crear y ejecutar trabajos de MapReduce en cada conjunto de datos. En 2007, Apache Pig se abrió a través de la incubadora Apache. En 2008, se lanzó la primera versión de Apache Pig. En 2010, Apache Pig se graduó como un proyecto de alto nivel de Apache.
Arquitectura de Apache Pig
El lenguaje utilizado para analizar datos en Hadoop usando Pig se conoce como Pig Latin. Es un lenguaje de procesamiento de datos de alto nivel que proporciona un amplio conjunto de tipos de datos y operadores para realizar diversas operaciones en los datos.
Para realizar una tarea en particular, los programadores que usan Pig deben escribir un script Pig usando Pig Latin y ejecutarlo utilizando cualquiera de los mecanismos de ejecución (Grunt Shell, UDFs, Embedded). Después de la ejecución, estos scripts pasan por una serie de transformaciones aplicadas por Pig Framework para producir el resultado deseado.
Internamente, Apache Pig convierte estos scripts en una serie de trabajos de MapReduce, lo que facilita el trabajo del programador. La arquitectura de Apache Pig se muestra a continuación.
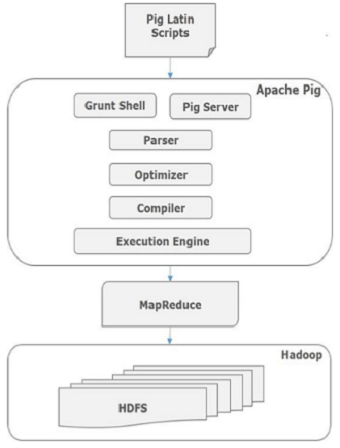
Componentes de Apache Pig
Como se muestra en la figura, hay varios componentes en el marco de Apache Pig. Echemos un vistazo a los componentes principales.
Analizador
Inicialmente, los scripts de Pig son manejados por el analizador. Comprueba la sintaxis del script, realiza la verificación de tipos y otras comprobaciones. La salida del analizador es un DAG (grafo acíclico dirigido), que representa las sentencias Pig Latin y los operadores lógicos.
En el DAG, los operadores lógicos del script se representan como nodos y los flujos de datos se representan como bordes.
Optimizador
El plan lógico (DAG) se pasa al optimizador lógico, que realiza optimizaciones lógicas, como proyección y pushdown.
Compilador
El compilador compila el plan lógico optimizado en una serie de trabajos de MapReduce.
Motor de ejecución
Finalmente, los trabajos de MapReduce se envían a Hadoop en un orden determinado. Estos trabajos de MapReduce se ejecutan en Hadoop y producen los resultados deseados.
Modelo de datos de Pig Latin
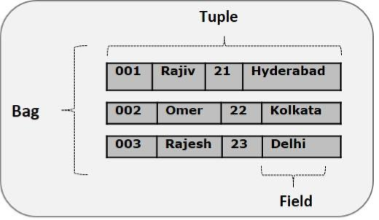
El modelo de datos de Pig Latin está completamente anidado y permite tipos de datos complejos no atómicos como mapa y tupla. A continuación se muestra la representación diagramática del modelo de datos de Pig Latin.
Átomo
Cualquier valor individual en Pig Latin, independientemente de su tipo de datos, se conoce como átomo. Se almacena como una cadena y se puede utilizar como cadena o número. int, long, float, double, chararray y bytearray son los valores atómicos de Pig. Una pieza de datos o un valor atómico simple se conoce como campo.
Ejemplo: ‘raja’ o ’30’
Tupla
Un registro formado por un conjunto ordenado de campos se conoce como tupla. Los campos pueden ser de cualquier tipo. Una tupla es similar a una fila en una tabla de RDBMS.
Ejemplo: (Raja, 30)
Bolsa
Una bolsa es un conjunto desordenado de tuplas. En otras palabras, una colección de tuplas (no únicas) se conoce como bolsa. Cada tupla puede tener cualquier número de campos (esquema flexible). Una bolsa se representa con ‘{}’. Es similar a una tabla en RDBMS, pero a diferencia de una tabla en RDBMS, no es necesario que cada tupla contenga el mismo número de campos o que los campos en la misma posición (columna) tengan el mismo tipo.
Ejemplo: {(Raja, 30), (Mohammad, 45)}
Una bolsa puede ser un campo en una relación; en ese contexto, se conoce como bolsa interior.
Ejemplo: {Raja, 30, {9848022338, raja@gmail.com}}
Mapa
Un mapa (o mapa de datos) es un conjunto de pares clave-valor. La clave debe ser de tipo chararray y debe ser única. El valor puede ser de cualquier tipo. Se representa con ‘[]’.
Ejemplo: [nombre#Raja, edad#30]
Relación
Una relación es una bolsa de tuplas. Las relaciones en Pig Latin no están ordenadas (no hay garantía de que las tuplas se procesen en un orden particular).
Instalación de Apache Pig
Este capítulo explica cómo descargar, instalar y configurar Apache Pig en su sistema.
Requisitos previos
Es esencial tener Hadoop y Java instalados en su sistema antes de instalar Apache Pig. Por lo tanto, antes de instalar Apache Pig, instale Hadoop y Java siguiendo los pasos que se indican en el siguiente enlace:
http://www.tutorialspoint.com/hadoop/hadoop_enviornment_setup.htm
Descargar Apache Pig
Primero, descargue la última versión de Apache Pig del siguiente sitio web: https://pig.apache.org/
Paso 1
Abra la página de inicio del sitio web de Apache Pig. En la sección Noticias, haga clic en el enlace de la página de publicación como se muestra en la siguiente imagen.
Paso 2
Al hacer clic en el enlace especificado, será redirigido a la página Apache Pig Releases. En esta página, en la sección de descargas, tendrá dos enlaces: Pig 0.8 y posterior y Pig 0.7 y anteriores. Haga clic en el enlace Pig 0.8 y posterior para ser redirigido a la página con un conjunto de espejos.
Paso 3
Elija y haga clic en cualquiera de estos espejos como se muestra a continuación.
Paso 4
Estos espejos lo llevarán a la página Pig Releases. Esta página contiene varias versiones de Apache Pig. Haga clic en la última versión.
Paso 5
Dentro de estas carpetas, encontrará los archivos fuente y binarios de Apache Pig en varias distribuciones. Descargue los archivos tar de los archivos fuente y binarios de Apache Pig 0.15: pig-0.15.0-src.tar.gz y pig-0.15.0.tar.gz.
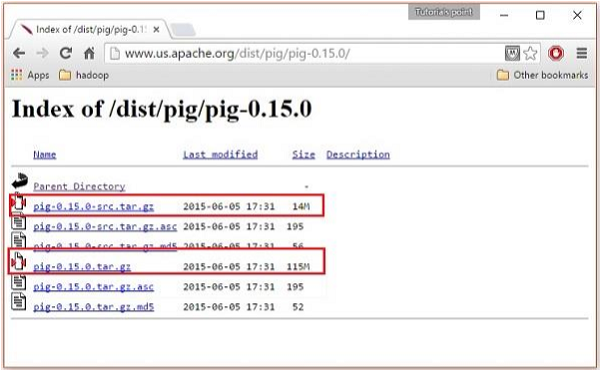
Instalar Apache Pig
Después de descargar el software Apache Pig, instálelo en su entorno Linux siguiendo los pasos que se detallan a continuación.
Paso 1
Cree un directorio llamado Pig en el mismo directorio donde se instalaron los directorios de instalación de Hadoop, Java y otro software. (En nuestro tutorial, hemos creado el directorio Pig en el usuario llamado Hadoop).
$ mkdir Pig
Paso 2
Extraiga los archivos tar descargados como se muestra a continuación.
$ cd Downloads/ $ tar zxvf pig-0.15.0-src.tar.gz $ tar zxvf pig-0.15.0.tar.gz
Paso 3
Mueva el contenido del archivo pig-0.15.0-src.tar.gz al directorio Pig creado anteriormente como se muestra a continuación.
$ mv pig-0.15.0-src.tar.gz/* /home/Hadoop/Pig/
Configurar Apache Pig
Después de instalar Apache Pig, debemos configurarlo. Para configurarlo, necesitamos editar dos archivos: .bashrc y pig.properties.
Archivo .bashrc
En el archivo .bashrc, configure las siguientes variables:
Variable PIG_HOME a la carpeta de instalación de Apache Pig.
Variable de entorno PATH a la carpeta bin.
Variable de entorno PIG_CLASSPATH a la carpeta conf de las instalaciones de Hadoop (el directorio que contiene los archivos core-site.xml, hdfs-site.xml y mapred-site.xml).
export PIG_HOME=/home/Hadoop/Pig export PATH=$PATH:/home/Hadoop/pig/bin export PIG_CLASSPATH=$HADOOP_HOME/conf
Archivo pig.properties
En la carpeta conf de Pig, tenemos un archivo llamado pig.properties. En el archivo pig.properties, puede establecer varios parámetros como se indica a continuación.
pig -h properties
Se admiten las siguientes propiedades:
Logging: verbose = true|false; default is false. This property is the same as -v switch
brief=true|false; default is false. This property is the same as -b switch
debug=OFF|ERROR|WARN|INFO|DEBUG; default is INFO. This property is the same as -d switch
aggregate.warning = true|false; default is true. If true, prints count of warnings of each type rather than logging each warning.
Performance tuning: pig.cachedbag.memusage=; default is 0.2 (20% of all memory). Note that this memory is shared across all large bags used by the application.
pig.skewedjoin.reduce.memusagea=; default is 0.3 (30% of all memory). Specifies the fraction of heap available for the reducer to perform the join.
pig.exec.nocombiner = true|false; default is false. Only disable combiner as a temporary workaround for problems.
opt.multiquery = true|false; multiquery is on by default. Only disable multiquery as a temporary workaround for problems.
opt.fetch=true|false; fetch is on by default. Scripts containing Filter, Foreach, Limit, Stream, and Union can be dumped without MR jobs.
pig.tmpfilecompression = true|false; compression is off by default. Determines whether output of intermediate jobs is compressed.
pig.tmpfilecompression.codec = lzo|gzip; default is gzip. Used in conjunction with pig.tmpfilecompression. Defines compression type.
pig.noSplitCombination = true|false. Split combination is on by default. Determines if multiple small files are combined into a single map.
pig.exec.mapPartAgg = true|false. Default is false. Determines if partial aggregation is done within map phase, before records are sent to combiner.
pig.exec.mapPartAgg.minReduction=. Default is 10. If the in-map partial aggregation does not reduce the output num records by this factor, it gets disabled.
Miscellaneous: exectype = mapreduce|tez|local; default is mapreduce. This property is the same as -x switch
pig.additional.jars.uris=. Used in place of register command.
udf.import.list=. Used to avoid package names in UDF.
stop.on.failure = true|false; default is false. Set to true to terminate on the first error.
pig.datetime.default.tz=. e.g. +08:00. Default is the default timezone of the host. Determines the timezone used to handle datetime datatype and UDFs.
Additionally, any Hadoop property can be specified.Verificar la instalación
Verifique la instalación de Apache Pig escribiendo el comando de versión. Si la instalación es exitosa, obtendrá la versión de Apache Pig como se muestra a continuación.
$ pig --version Apache Pig version 0.15.0 (r1682971) compiled Jun 01 2015, 11:44:35
Ejecución de Apache Pig
En el capítulo anterior, explicamos cómo instalar Apache Pig. En este capítulo, discutiremos cómo ejecutar Apache Pig.
Modos de ejecución de Apache Pig
Puede ejecutar Apache Pig en dos modos: modo local y modo MapReduce/HDFS.
Modo local
En este modo, todos los archivos se instalan y ejecutan desde el host local y el sistema de archivos local. No hay necesidad de Hadoop o HDFS. Este modo generalmente se usa para fines de prueba.
Modo MapReduce/HDFS
El modo MapReduce/HDFS es donde cargamos o procesamos los datos que existen en el Hadoop File System (HDFS) utilizando Apache Pig. En este modo, cada vez que ejecutamos sentencias Pig Latin para procesar los datos, se invoca un trabajo de MapReduce en segundo plano para realizar una operación particular en los datos que existen en HDFS.
Mecanismos de ejecución de Apache Pig
Los scripts de Apache Pig se pueden ejecutar de tres maneras: modo interactivo, modo por lotes y modo incrustado.
Modo interactivo (Grunt shell): puede ejecutar Apache Pig en modo interactivo utilizando Grunt shell. En este shell, puede ingresar las sentencias Pig Latin y obtener la salida (usando el operador dump).
Modo por lotes (script): puede ejecutar Apache Pig en modo por lotes escribiendo el script Pig Latin en un solo archivo con la extensión .pig.
Modo incrustado (UDF): Apache Pig ofrece la posibilidad de definir nuestras propias funciones (User Defined Functions) en lenguajes de programación como Java y usarlas en nuestro script.
Invocar Grunt Shell
Puede invocar Grunt shell en el modo deseado (local/MapReduce) usando la opción -x como se muestra a continuación.
| Modo local | Modo MapReduce |
|---|---|
Comando: $ ./pig -x local | Comando: $ ./pig -x mapreduce |
Salida: 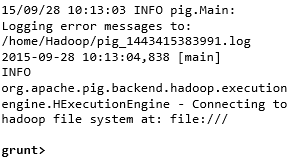 | Salida:  |
Cualquiera de estos comandos muestra el prompt de Grunt shell como se muestra a continuación.
grunt>
Puede salir de Grunt shell usando ‘ctrl + d’.
Después de invocar Grunt shell, puede ejecutar un script Pig ingresando directamente las declaraciones Pig Latin en él.
grunt> customers = LOAD 'customers.txt' USING PigStorage(',');Ejecutar Apache Pig en modo Batch
Puede escribir un script completo de Pig Latin en un archivo y ejecutarlo usando el comando pig. Supongamos que tenemos un script Pig en un archivo llamado sample_script.pig como se muestra a continuación.
sample_script.pig
student = LOAD 'hdfs://localhost:9000/pig_data/student.txt' USING PigStorage(',') as (id:int,name:chararray,city:chararray); DUMP student;
Ahora puede ejecutar el script en el archivo anterior como se muestra a continuación.
| Modo local | Modo MapReduce |
|---|---|
| $ pig -x local sample_script.pig | $ pig -x mapreduce sample_script.pig |
Nota: Discutiremos en detalle cómo ejecutar un script Pig en modo Batch y en modo incrustado en los capítulos siguientes.
Apache Pig – Grunt Shell
Después de invocar Grunt Shell, puede ejecutar sus scripts Pig en el shell. Además, Grunt Shell proporciona ciertos comandos de shell y utilidad útiles. Este capítulo explica los comandos de shell y utilidad proporcionados por Grunt Shell.
Nota: En algunas partes de este capítulo, se utilizan comandos como LOAD y STORE. Consulte los capítulos respectivos para obtener información detallada sobre ellos.
Comandos de Shell
Grunt Shell de Apache Pig se usa principalmente para escribir scripts Pig Latin. Antes de eso, podemos invocar cualquier comando de shell usando sh y fs.
Comando sh
Usando el comando sh, podemos invocar cualquier comando de shell desde Grunt Shell. Usando el comando sh de Grunt Shell, no podemos ejecutar comandos que son parte del entorno del shell (ej.: cd).
Sintaxis
A continuación se muestra la sintaxis del comando sh.
grunt> sh comando_del_shell parámetros
Ejemplo
Podemos invocar el comando ls del shell de Linux desde Grunt Shell usando la opción sh como se muestra a continuación. En este ejemplo, lista los archivos en el directorio /pig/bin/.
grunt> sh ls pig pig_1444799121955.log pig.cmd pig.py
Comando fs
Usando el comando fs, podemos invocar cualquier comando de FsShell desde Grunt Shell.
Sintaxis
A continuación se muestra la sintaxis del comando fs.
grunt> fs comando_del_sistema_de_archivos parámetros
Ejemplo
Podemos invocar el comando ls de HDFS desde Grunt Shell usando el comando fs. En el siguiente ejemplo, lista los archivos en el directorio raíz de HDFS.
grunt> fs -ls Found 3 items drwxrwxrwx - Hadoop supergroup 0 2015-09-08 14:13 Hbase drwxr-xr-x - Hadoop supergroup 0 2015-09-09 14:52 seqgen_data drwxr-xr-x - Hadoop supergroup 0 2015-09-08 11:30 twitter_data
De la misma manera, podemos invocar todos los demás comandos de shell del sistema de archivos desde Grunt Shell usando el comando fs.
Comandos de utilidad
Grunt Shell proporciona un conjunto de comandos de utilidad. Estos incluyen comandos de utilidad como clear, help, history, quit y set; y comandos como exec, kill y run para controlar Pig desde Grunt Shell. A continuación, se describe los comandos de utilidad proporcionados por Grunt Shell.
Comando clear
El comando clear se usa para borrar la pantalla de Grunt Shell.
Sintaxis
Puede borrar la pantalla de Grunt Shell usando el comando clear como se muestra a continuación.
grunt> clear
Comando help
El comando help proporciona una lista de comandos o propiedades de Pig.
Uso
Puede obtener una lista de comandos Pig usando el comando help como se muestra a continuación.
grunt> help Commands: ; - See the PigLatin manual for details: http://hadoop.apache.org/pig File system commands: fs - Equivalent to Hadoop dfs command: http://hadoop.apache.org/common/docs/current/hdfs_shell.html Diagnostic Commands: describe [relation_name] [-out path] [-brief] [-dot|-xml] [-param key=value] [-param_file file_name] [alias] - Show the execution plan to compute the alias or for entire script. -script - Explain the entire script. -out - Store the output into directory rather than print to stdout. -brief - Don't expand nested plans (presenting a smaller graph for overview). -dot - Generate the output in .dot format. Default is text format. -xml - Generate the output in .xml format. Default is text format. -param - See parameter substitution for details. alias - Alias to explain. dump alias - Compute the alias and writes the results to stdout. Utility Commands: exec [-param key=param_value] [-param_file file_name] ...